Retrieval-Augmented Generation (RAG) AI Agent with Kumologica
Retrieval-Augmented Generation (RAG) is a cutting-edge approach in natural language processing (NLP) that combines document retrieval and generation. In a RAG system, an AI agent first retrieves relevant documents from a database or knowledge base and then uses those documents to augment the generation of responses, typically via a large language models like OpenAI or AnthropicAI.
In this blog, we will walk through the process of implementing an AI agent using Kumologica VectorStore for document retrieval, OpenAInode for text generation, and prompt engineering to guide the model in generating accurate, document-backed answers.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) merges two core NLP techniques:
- Document Retrieval: Given a query, relevant documents are fetched from a store based on semantic similarity.
- Text Generation: A generative model (like GPT) is used to synthesize coherent responses using the retrieved documents as context.
RAG is particularly powerful for question-answering tasks where the model needs to pull specific knowledge from an internal source and generate accurate responses. It allows a model to scale beyond its internal knowledge by leveraging external sources in real-time.
System Overview
Our Example RAG AI agent written in Kumologica will operate in the following steps:
- Embedding Creation: Text data (documents or chunks) are embedded into vector Store using OpenAI’s embeddings.
- User Query Processing: Executing Query submitted by the user:
- Retrieving Documents: The most relevant documents are retrieved from the vector store using similarity search.
- Prompt Engineering: The retrieved documents are formatted into a carefully crafted prompt to elicit high-quality responses from the model.
- Text Generation: These retrieved documents are passed to OpenAI’s GPT model as context to generate an answer.
Steps to Implement a RAG AI Agent
The complete source code is available in kumologica demos github repository
1. Setting Up Project
Create environment variable with your OpenAI Api Key, checkout kumologica demos and run Kumologica Designer
export OPENAI_API_KEY=your api key here
# go to your development directory
# cd <your projects directory>
# checkout kumologica demos
git clone https://github.com/KumologicaHQ/kumologica-demos.git
# go to rag demo
cd kumologica-demos/ai/rag-memoryvectorstore
# build contrib dependencies
npm install
# open kumologica designer with project from current directory
kl open .2. Creating and Storing Documents in the Vector Store
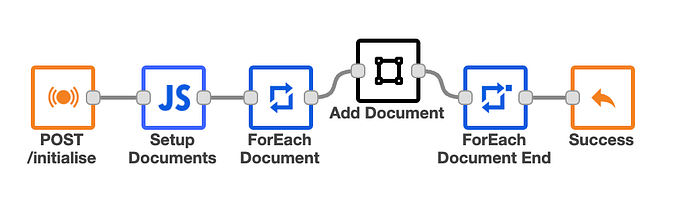
The AI agent will work by embedding documents into a vector store. For simplicity the provided example contains 5 simple documents hardcoded into array variable (Function node: “Setup Documents”).
“grulp is an animal”,
“grapl is a plant”,
“grulp feeds on grapl”,
“grulp is herbivore”,
“grapl doesn’t produce flowers”
The content of these documents is fabricated to ensure that it does not overlap with any information contained in OpenAI’s pre-trained models.
The above 5 documents are loaded into Memory Vector Store with following parameters:
- Splitter: Recursive Character Text Splitter, chunk size 50, chunk overlap 5
- Embeddings: OpenAI text-embedding-3-small
The logic described above has been implemented in the provided example and is accessible via the POST /initialise API endpoint.
3. User Query Processing
The user’s query processing is a simple flow containing 3 steps:
- Search Vector Store
- Prompt Creation
- OpenAI Query
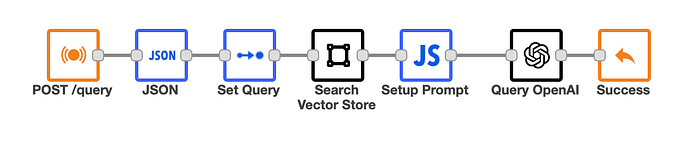
Retrieving Documents from the Vector Store
Once the vector store is populated, we can perform similarity searches to find the most relevant documents. The example require return of 4 documents.
Prompt Engineering for OpenAI GPT Model
To guide the generative model in creating precise and informative responses, retrieved documents are formatted into a structured prompt.
Key principles:
- Inject Context: Provide the retrieved documents clearly.
- Set Expectations: Tell the model to use the provided documents in its response.
- Avoid Noise: Use only the top
kdocuments to avoid overwhelming the model.
The prompt is created in Function node “Setup Prompt” as follows:
// msg.payload contains response from vector store in json format
// {["pageContext: "...", "metadata": "..."]}
// extract pageContext from the vector store response
const res = msg.payload.map(doc => doc.pageContext).join("\n");
// prompt is stored in msg.system variable
msg.system = `
You are an AI assistant tasked with answering questions using the following documents:
"${res}"
Now, based on the above documents, answer the following query:
`;
// the user query was extracted from http POST /query call and
// stored in msg.query variable, see "Set Query" nodeOpenAI Q&A
Final step of query processing is an invocation of OpenAI SingleQ&A operation with prompt stored in msg.system variable and user’s query stored in msg.query variable.
Testing
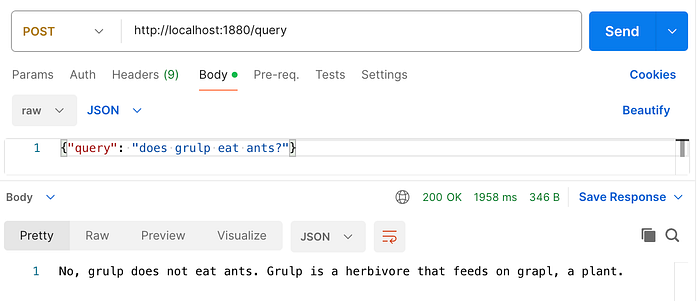
Both: creation of documents in vector store and query are exposed as apis and are easily testable in postman.
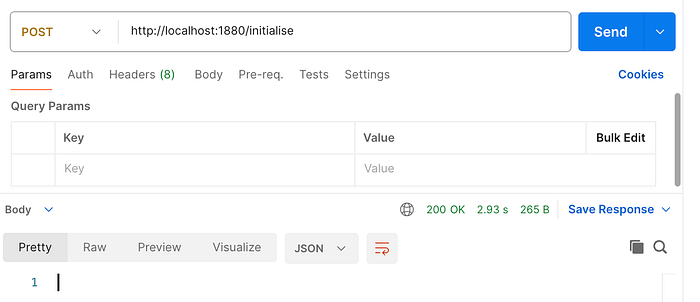
First: execute POST /initialise to load ducuments into memory vector store
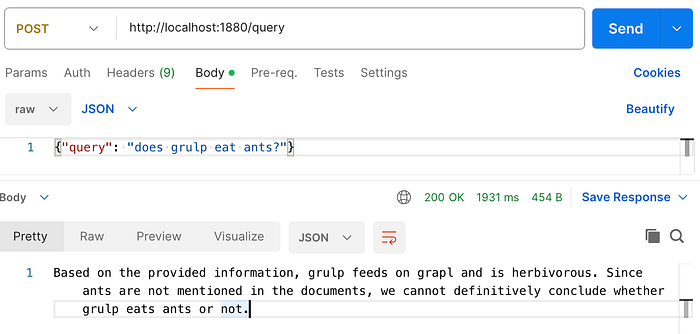
Second: Execute sample query, notice the difference in the response depending on OpenAI model:
gpt-3.5-turbo:
gpt-4:
Conclusion
By following this structure, you can implement an effective RAG AI agent using Kumologica VectorStore node with OpenAI or AnthropicAI nodes. With this approach, you can retrieve highly relevant documents in response to a query and generate answers using the contextual knowledge provided by these documents. Prompt engineering plays a crucial role in ensuring that the generative model can accurately synthesise information from the retrieved documents.
This RAG-based approach allows your AI agent to go beyond its internal knowledge and make use of internal data in real time, enabling it to provide more up-to-date and accurate answers across a variety of use cases.
Next Steps
In future posts, we will explore:
- Scaling this architecture with more advanced vector stores like FAISS or Pinecone.
- Using more advanced prompt engineering techniques for better generation results.
- Applying the RAG architecture to other tasks like summarisation and document classification.
More information
- For more information about Kumologica SDK Installation see: Kumologica SDK Installation
- Join our community group on discord
- Visit kumologica.com for information about sdk, designer, documentation, tutorials, support and professional services.